Ever wondered what a kafka partition is? Or why assigning them randomly might be a bad idea? Last October I presented at Spoud.io’s streaming meetups on the topic of Kafka Partitioning.
The goal was to illustrate how the enterprise context can make simple things more challenging, the assorted counter-measures and lessons learnt from a migration project.
If you’re into watching videos, the 15 minutes presentation is available on Youtube, with slides at the end of the post. For a TL/DR with the most important drawings and conclusions, read on.
The Gist
Say you are a dev tasked to work with some data thrown at you through a Kafka topic. One morning, you run into this issue:
The messages I get from Kafka are out of order, can anybody help?
Let’s skip the boring part where you figure out where the data comes from, which can be an adventure on its own, and jump to the conclusion handed to you by the fellow engineer responsible for writing to that topic:
Nope, these messages should definitely be ordered: I’m only writing monotonously increasing values to kafka!
Assuming everyone is acting in goo faith, what could possibly explain this situation?
(Randomly) Partitioning
One important thing to remember, with kafka, is that ordering is guaranteed within a partition. Ergo, whenever you run into ordering issues, multiple partitions are likely involved (if not to blame).
The simplest situation where we can run into ordering problems is illustrated below:
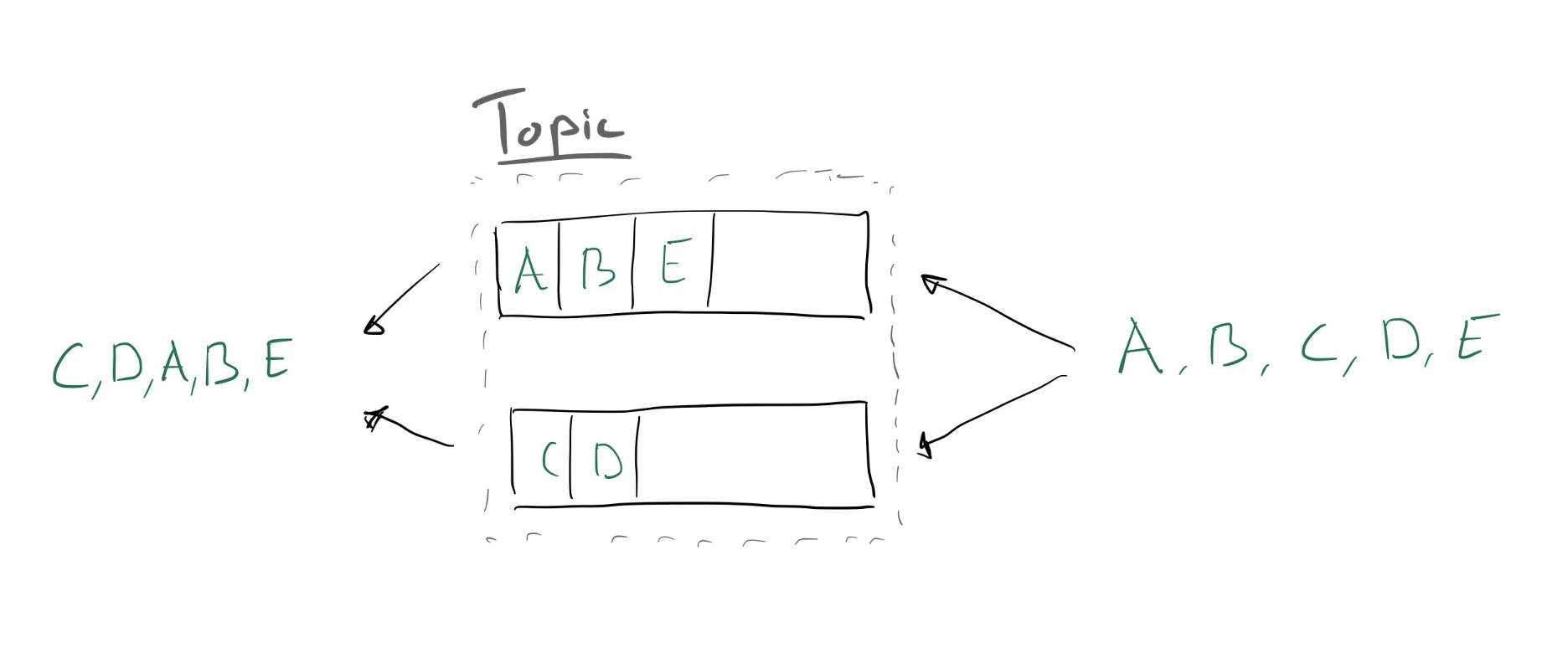
The consumer, on the left, takes messages from all partitions and reassembles them into a single stream: as ordering is not guaranteed outside of a single partition, you end up with un-ordered messages. The cause of this is generally a producer that sends messages out to random partitions instead of using a partition key.
The temptation
If you somehow really need to have things in order, you may be tempted by the following:
Easy! We can just repartition!
Implementing that idea, you might end up with this setup:
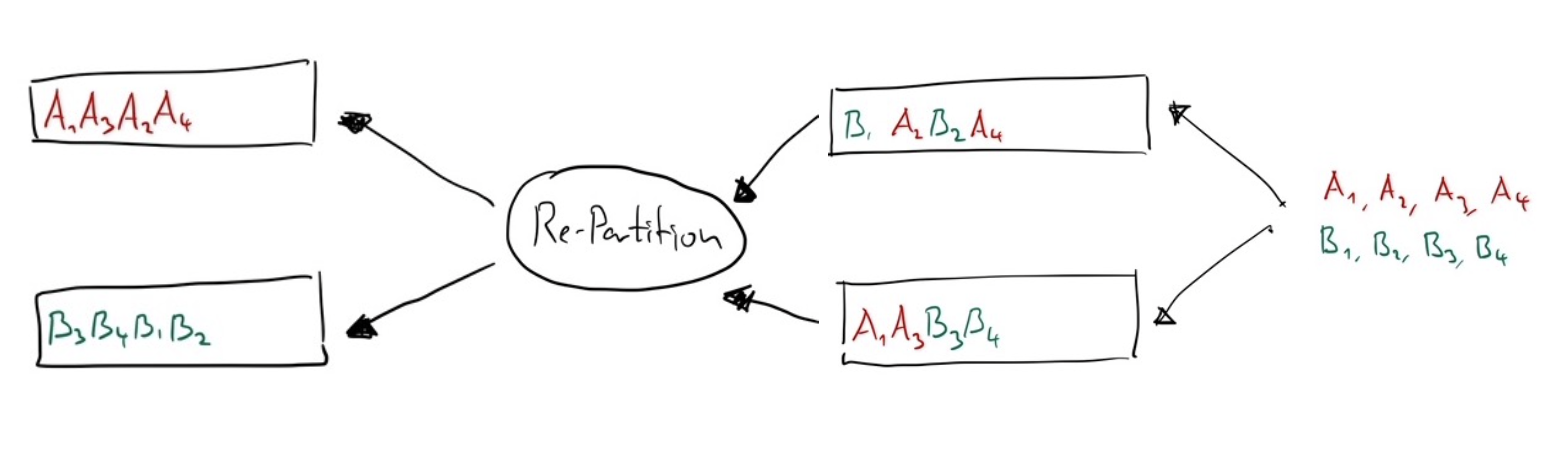
Neat! Messages with the same partition key are together, but at closer look, they are still out of order.
Hence, if you really really want things in order, you’ll have to add a re-ordering step:
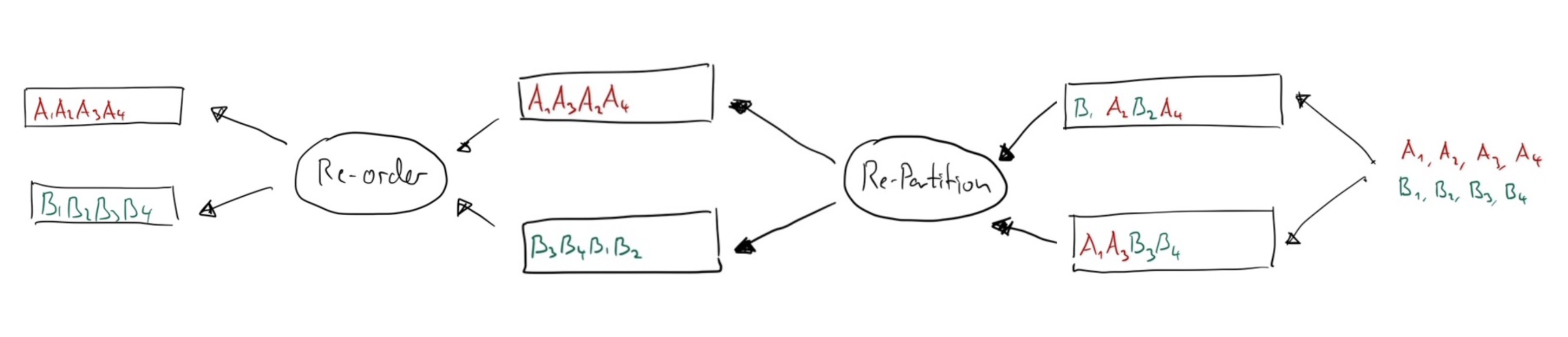
At this point, you can resume with your original task, and hopefully be done before the week-end arrives.
Downsides
There might be cases where you can’t avoid this, but before trying too hard to convince yourself that you are in such a situation, consider its downsides. This is what you’ll be adding to your system:
- Latency, as you need to wait for an arbitrary amount of time to convince yourself that no out-of-order message will arrive anymore
- Complexity, with an additional processing step that needs to be maintained
- Resources, as additional Memory, CPU and Disk space are required
The above may quickly outweight the annoyance of going back to your producer and getting them to partition their data correctly. Consider the optimal situation where messages directly end up where they need to:

Voilà! Plain and simple! Comparing it to the previous pipeline we have a good argument for doing things properly vs. doing them quickly:
- You can consume messages as soon as they are available and build truly reactive systems
- Easier to reason about as you directly get what was written into the topic
- No intermediary processing steps that eat resources and can fail
Depending on the type of systems you are building, these are no small benefits!
Conclusion
In general I’ve found that if you’re about to ship randomly partitioned data, you’d better directly pipe it to /dev/null: so always carefully consider the consequences.
Looking beyond the pure technical and immediate mitigations, it is interesting to see that organisational arrangements can be the underlying catalysts to these situations: for a glimpse at these, check out the slides or the entire presentation.