Same shape, same thing? Networking can be hard. Value, virtue and the benefits of simplicity.
Ever got into a discussion comparing the vices and virtues of monolithic versus multi- or micro-service based approaches? They are such a lovely way to enliven a boring day at the office! Especially if held outside of any constraining context.
For the present discussion, I’ll assume that a modicum of (serious) design and architecture has been done already: you should really remember that a service oriented architecture or a huge monolith (regardless of its clunkiness or perfect modularity) are not going to fix a bad architecture1.
The Whiteboard Drawing
Let us assume that after a thoughtful requirement digestion, the development team concluded that these could be fulfilled using the following conceptual approach:
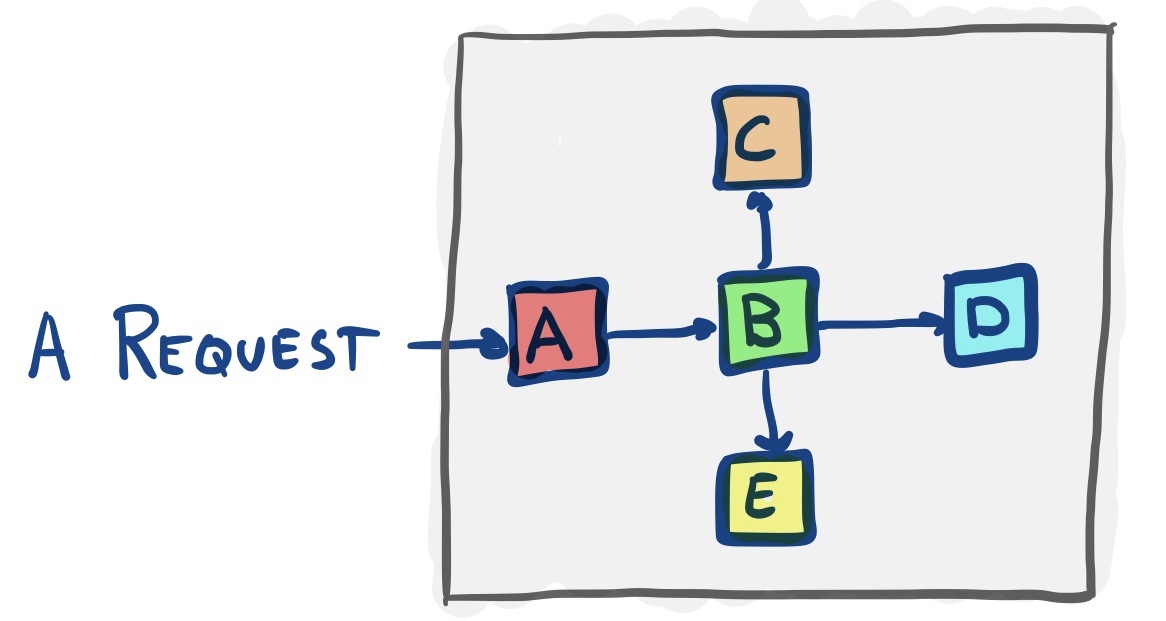
Request comes in, gets authenticated (A), forwarded to the business logic (B), which checks something with a configuration module (C), looks up a few records from a database (D) and ends with logging some facts (E).
All good: time to think about the implementation.
Like in every good group of people writing software, you have representatives of both team monolith and team micro-service. –“Let’s add modules to the monolith”, say the former, –"Let’s add services" the latter reply.
How much does it matter, assuming everyone agrees on the high level approach? Let us look at a possible proposal from each side:
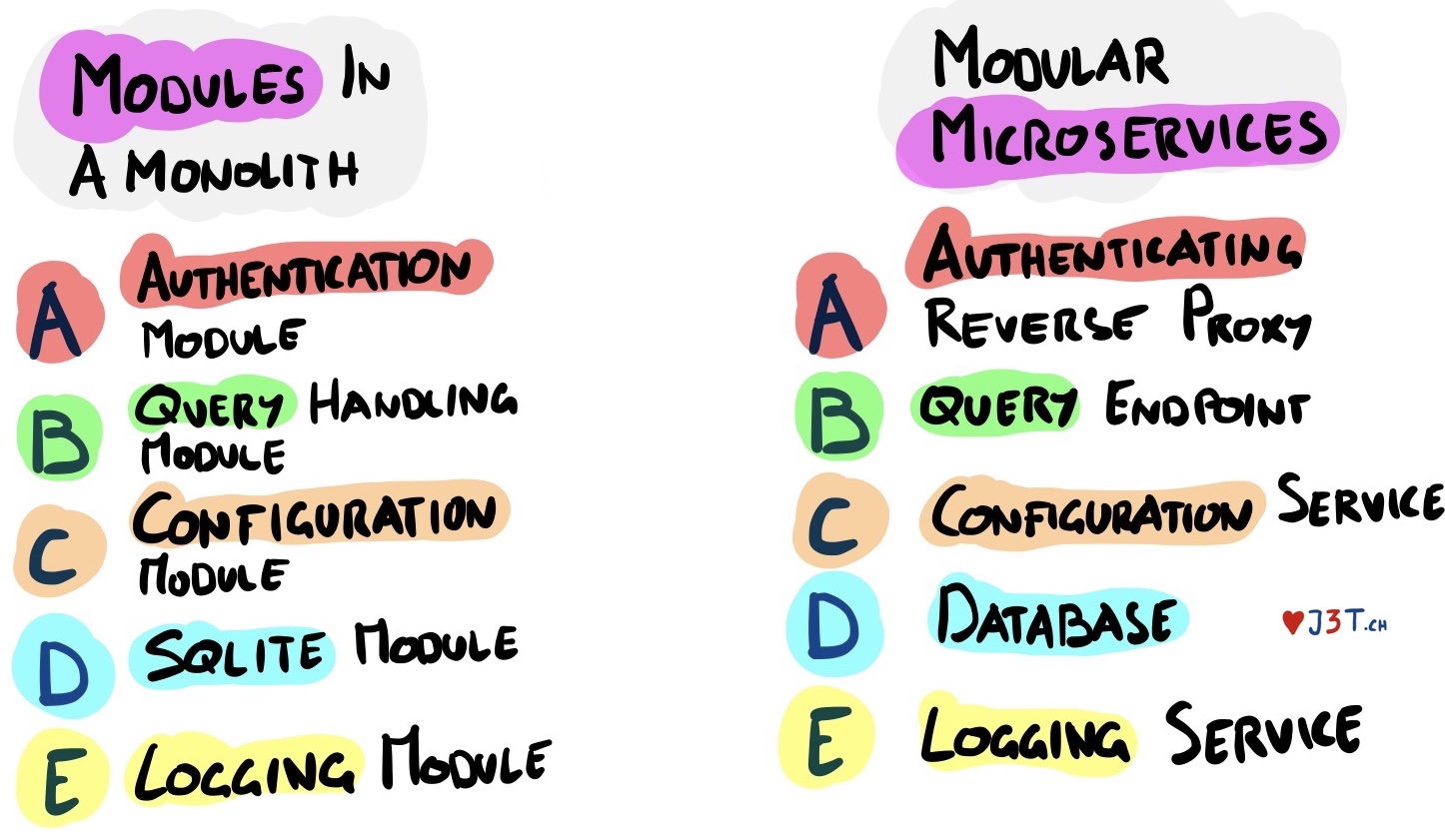
Some implementation details change: a reverse proxy instead of an authentication module, a full database instead of relying on sqlite, or a dedicated endpoint handling the request and calling other services instead of direct function or method calls. In both cases, the overall approach remains the same: the code underpinning each element will be similar, if not identical.
Hence, the discussion should not focus on which approach is best in the absolute but what the trade-offs which make sense in our current context are.
The rest of this post dwelves on that topic.
Downside Focus
I’m assuming that the reader is aware of the general benefits of micro-services and won’t revisit these – there’s a whole swath of the internet dedicated to this, and the general bias seems justifiably be in favor of services.
Instead, I’ll focus on the extra content you often get when moving away from a monolith: you usually obtain a bit more than what you bargained for, and not all of it is a net win.
Libraries Ain’t Micro-Services – When To Split?
Is the idea of splitting out functionality to services mainly exciting to you because it lets you hot-swap some business logic? Don’t worry, I’ve been there too: it’s one of the interesting aspects that got me intrigued at first! But let me say straight away that this might not be the best motivation for a service oriented architecture.
Cheap & fast computational work that can be done in-place (ie, directly within the application where it is required) should probably not be moved to a separate service: the benefits would be low to non-existing. Such things belong into a shared toolbox and there’s no problem using them in multiple places – think of parsing utilities, input validation code or formatters.
You can share concepts or you can share resources, and services should primarily help with sharing resources2: a library mostly does useful things in place while a service does useful things elsewhere. You’ll get access to the service using a client or client library.
If you’re looking into distributing concepts, start with a library! Which you can always wrap into a service and make available remotely at a later stage, when splitting it of becomes necessary. And should there be doubts about whether a split is necessary, it’s probably safer to wait.
Anatomy of a (replaced) function call
The concept versus resource question is important to consider because moving things to separate services comes with a cost. And these are in fact higher than what you’d expect if you think of it as simply moving code around.
If you’re slicing things out of a monolith to move them to separate services, you’ll likely be starting from what are function or method calls that do reasonably simple things. At most, they do some scheduling or handing-off to other threads or processes: nothing too fancy3.
From now on, said function calls will involve much more sheananigans and have a far greater chance of failing. Have you ever pondered the possibility that a simple operation – say, an addition – might fail? Probably not. What if you rely on a service to do the addition instead?
In the multi-service world, reasoning about failure becomes a fundamental requirement: this is not bad per se – thinking about failure modes is an essential skill for an engineer – but might be specially annoying as it will add tons of possibilities for unexpected behavior in places where there were none before. In other words, you’re increasing the degrees of freedom available to your system to mess with your sanity. And you will notice.
Local Addition
Let us look at what is involved with replacing a local function call with a remote procedure call (aka ‘RPC’ or just ‘querying another service'). Let us continue with our addition example:
/** Incredibly efficient and safe additions. **/
int add(int a, int b) throws ArithmeticException {
return Math.addExact(value, 1)
}
// Do an addition
int r = add(1,2)
If you need to do an addition, you:
- call the function
- do stuff with the returned value
Possibly it throws an exception, which you need to handle or ignore. Otherwise, you’re done.
Remote Addition
Now, let’s say that we’ve decided to move add to a separate service so that the number crunching in our organisation gets neatly concentrated to a few dedicated hosts:
// Instantiate a client for the service
AdditionClient client = new AdditionClient("addition-service-host", port)
// Do an addition
int r = client.add(1,2)
What’s happening under the hood in this new version? If we’re a very serious shop, it could look like this:
- Open network socket
- Negotiate SSL handshake (we want to be safe, do we!)
- Authenticate (not everyone can freely do additions!)
- Serialize request and relevant data (big or little endian?)
- Write to socket (how big are your TCP windows?)
- Wait for bytes to come back (the service is really far!)
- Deserialize reply (what’s the endianness again?)
This becomes quite involved: the amount of things that can go wrong literally explodes.
Possible failures during a call to the service could be:
- DNS resolution failure: can’t even find out where to send the request to!
- Network related failures, for which causes can be:
- Misconfigured firewall
- Misconfigured router
- Broken VPN tunnel
- Socket open timeout (may or may not be network related)
- Socket timeout while open (same)
- Socket unexpectedly closes (same)
- Bandwidth limitation
- Expired Server Certificate
- Bad credentials, because:
- Just wrong creds, sorry, copy-pasta error.
- Creds were rotated, somehow weren’t updated. Oops.
- Encoding or escaping error. Env vars can be annoying.
- Bad proxy configuration
- Unexpected data formats & results
- Because of a server bug
- Because of a newer server version
- Because of an older server version
- An exception thrown in code used by the service
- The service is simply down
Obviously, good client libraries will try to make the above as tractable as possible and make it easy for you to manage the various corner cases. Still, failures will happen eventually, and sometimes for reasons entirely out of your control4.
Developpers (ot at least a few on the team) will need some level of understanding about DNS, networks, authentication and possibly firewalls! This will come on top of everything else that’s already expected from them (orchestration, distributed systems, …) and we’ve not even mentioned the subject of debugging!
The goal here is not to dunk on micro-services. You must simply be aware that it requires more than what a simple architectural schema suggests. Spreading out and scaling up an architecture also means increasing your knowledge about distributed systems by a lot.
For anyone who loves to learn new things, it’s a boon!
The build & release engineering perspective
Switching to multiple services from a monolith also has impacts beyond the pure code layer. Some common questions that might arise:
- “Should we have one repository per service?"
- “Where should common utilities live?"
- “Can we now use different programming languages or frameworks to implement different services?"
- “How do we enforce good practices across all services?"
This will impact your CI & CD setup, your code hosting, your build system(s) and the way you write and review software. Furthermore, if multiple artifacts are built from the same repo, it might impact build times – for better or worse, it depends.
More importantly, it will quickly make reasoning about what you build and deploy harder: if everyone works on the same hunk of code, it’s easy for all members of the team to have a rough idea of how things are built and deployed, and to keep the big picture in mind. Once things start being split by topic, product or specialty, it becomes more challenging to keep the overview. This is a serious challenge to a healthy team cognition.
My first reflex here is to recommend single or fat repos, at least until all options have been consciously (and seriously) evaluated: my experience shows that adding repositories easily begets even more repositories, leading to situations ala “when in doubt, just create a new repo”! Creating repos should really not become an act as benign as creating a directory. Ideally, it’s simply impossible.
A common fear about mono-repos in a micro-service context, is that it still feels too monolithic. This might stem from a conflation of different abstraction levels and is expanded upon over here. The main take away is that, if you have modular code, having monoliths or micro-services in a single repository is perfectly viable: the trade-offs happen at other levels.
Remember: Look At Shapes
This concludes our little foray into architectures and their shape: remember to keep an eye out for how some different things can be extremely similar, depending on the lense through which you’re looking at them.
For there are plenty of different things in our software universe, yet not as much than what we tend to imagine when we look purely at concepts.
-
Banach & Tarski have already proven this in 2005, as aptly reminded by this guy on Twitter. ↩︎
-
This is not always true: you could imagine that certain languages miss good libraries for addressing a particular problem space. In such a case it might make sense to expose functionality via services implemented in a more suitable language. Hiding implementation details from users, if you distribute your application, can be another valid motivation. ↩︎
-
Except if you’re already using more advanced frameworks such as ZIO: that does not solve the possibility of failure, but error propagation and handling will be much easier. ↩︎
-
Such as your cloud provider politely telling you “Sorry we messed up the routing to certain networks on our backbone last week”. ↩︎